
martes, 27 de noviembre de 2018
Prueba de hipótesis para la media, varianza y de las proporciones
Media
En vez de estimar el valor de un parámetro, a veces se debe decidir si una afirmación relativa a un parámetro es verdadera o falsa. Es decir, probar una hipótesis relativa a un parámetro. Se realiza una prueba de hipótesis cuando se desea probar una afirmación realizada acerca de un parámetro o parámetros de una población.
Una hipótesis es un enunciado acerca del valor de un parámetro (media, proporción, etc.).
Prueba de Hipótesis es un procedimiento basado en evidencia muestral (estadístico) y en la teoría de probabilidad (distribución muestral del estadístico) para determinar si una hipótesis es razonable y no debe rechazarse, o si es irrazonable y debe ser rechazada.
La hipótesis de que el parámetro de la población es igual a un valor determinado se conoce como hipótesis nula. Una hipótesis nula es siempre una de status quo o de no diferencia.

En toda prueba de hipótesis se presentan 3 casos de zonas críticas o llamadas también zonas de rechazo de la hipótesis nula, estos casos son los siguientes:
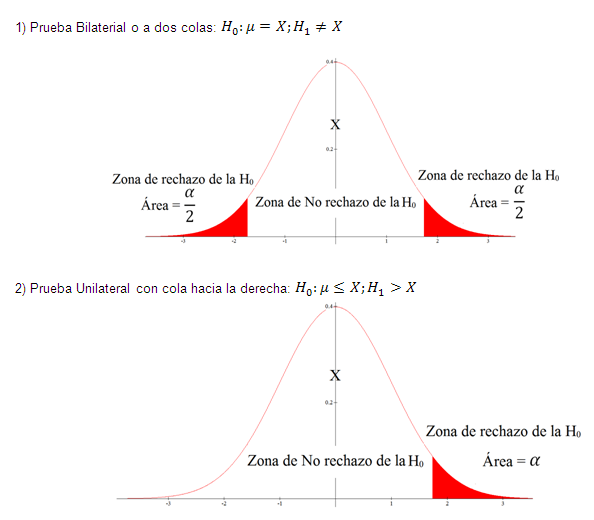
Varianza
Pruebas de hipótesis para una varianza Es un procedimiento para juzgar si una propiedad que se supone cumple una población estadística es compatible con lo observado en una muestra de dicha población en este caso la varianza, para ello formularemos dos Hipótesis (llamada "Hipótesis Nula") y (llamada "Hipótesis Alternativa"), con ellas realizaremos una o mas pruebas, para tratar de encontrar cual deberíamos rechazar. En este procedimiento lo que buscamos es, mediante unos criterios de rechazo preestablecidos, tratar de desmentir nuestra “Hipótesis Nula” por lo cual tomaríamos la “Hipótesis alternativa”, de lo contrario no rechazaríamos nuestra ”Hipótesis Nula” y desecharíamos la ”Hipótesis
Proporción
Las pruebas de proporciones son adecuadas cuando los datos que se están analizando constan de cuentas o frecuencias de elementos de dos o más clases. El objetivo de estas pruebas es evaluar las afirmaciones con respecto a una proporción (o Porcentaje) de población. Las pruebas se basan en la premisa de que una proporción muestral (es decir, x ocurrencias en n observaciones, o x/n) será igual a la proporción verdadera de la población si se toman márgenes o tolerancias para la variabilidad muestral. Las pruebas suelen enfocarse en la diferencia entre un número esperado de ocurrencias, suponiendo que una afirmación es verdadera, y el número observado realmente. La diferencia se compara con la variabilidad prescrita mediante una distribución de muestreo que tiene como base el supuesto de que  es realmente verdadera.
es realmente verdadera.
En muchos aspectos, las pruebas de proporciones se parecen a las pruebas de medias, excepto que, en el caso de las primeras, los datos muestrales se consideran como cuentas en lugar de como mediciones. Por ejemplo, las pruebas para medias y proporciones se pueden utilizar para evaluar afirmaciones con respecto a:
1) Un parámetro de población único (prueba de una muestra)
2) La igualdad de parámetros de dos poblaciones (prueba de dos muestras), y
3) La igualdad de parámetros de más de dos poblaciones (prueba de k muestras). Además, para tamaños grandes de muestras, la distribución de muestreo adecuada para pruebas de proporciones de una y dos muestras es aproximadamente normal, justo como sucede en el caso de pruebas de medias de una y dos muestras.
viernes, 23 de noviembre de 2018
intervalo de confianza para la varianza de distribución normal

A partir del estadístico

la fórmula para el intervalo de confianza, con nivel de confianza 1 − α es la siguiente

Donde χ2α/2 es el valor de una distribución ji-cuadrado con n − 1 grados de libertad que deja a su derecha una probabilidad de α/2.
Por ejemplo, dados los datos siguientes:
- Distribución poblacional: Normal
- Tamaño de muestra: 10
- Confianza deseada para el intervalo: 95 %
- Varianza muestral corregida: 38,5
Un intervalo de confianza al 95 % para la varianza de la distribución viene dado por:

que resulta, finalmente
intervalo de confianza para las proporciones



Existen dos alternativas a la hora de construir un intervalo de confianza para p:
- Considerar la aproximación asintótica de la distribución Binomial en la distribución Normal.
- Utilizar un método exacto.
Aproximación asintótica
Tiene la ventaja de la simplicidad en la expresión y en los cálculos, y es la más referenciada en la mayoría de textos de estadística. Se basa en la aproximación
que, trasladada a la frecuencia relativa, resulta
Tomando como estadístico pivote

que sigue una distribución N(0, 1), y añadiendo una corrección por continuidad al pasar de una variable discreta a una continua, se obtiene el intervalo de confianza asintótico:

donde zα/2 es el valor de una distribución Normal estándar que deja a su derecha una probabilidad de α/2 para un intervalo de confianza de (1 − α) · 100 %. Las condiciones generalmente aceptadas para considerar válida la aproximación asintótica anterior son:
El intervalo obtenido es un intervalo asintótico y por tanto condicionado a la validez de la aproximación utilizada. Una información más general sobre los intervalos de confianza asintóticos puede encontrase aquí.
Intervalo exacto
Aun cuando las condiciones anteriores no se verifiquen, es posible la construcción de un intervalo exacto, válido siempre pero algo más complicado en los cálculos. Es posible demostrar que un intervalo exacto para el parámetro p viene dado por los valores siguientes:

intervalos de confianza para la diferencia de medias
Supondremos la existencia de dos poblaciones sobre las que una variable determinada sigue una distribución Normal con idéntica varianza en las dos. Sobre la población 1, la variable sigue una distribución N(µ1, σ) y, sobre la población 2, sigue una distribución N(µ2, σ). Igualmente supondremos que disponemos de dos muestras aleatorias independientes, una para cada población, de tamaños muestrales n1 y n2 respectivamente.
El objetivo es construir un intervalo de confianza, con nivel de confianza (1 − α) · 100 %, para la diferencia de medias
µ1 − µ2
El método se basa en la construcción de una nueva variable D, definida como la diferencia de las medias muestrales para cada población
Esta variable, bajo la hipótesis de independencia de las muestras, sigue una distribución Normal de esperanza
µ1 − µ2
y de varianza

La estimación conjunta, a partir de las dos muestras, de la varianza común viene dada por la expresión

y, utilizando la propiedad de que la variable

sigue una distribución χ2 con n1 + n2 − 2 grados de libertad, podemos construir un estadístico pivote que siga una distribución t de Student y que nos proporciona la fórmula siguiente para el intervalo de confianza para la diferencia de medias:

donde tα/2 es el valor de una distribución t de Student con n1 + n2 − 2 grados de libertad que deja a su derecha una probabilidad de α/2.

miércoles, 24 de octubre de 2018
Estimadores
En estadística, un estimador es estadístico(esto es, una función de la muestra) usado para estimar un parámetro desconocido de la población. Por ejemplo, si se desea conocer el precio medio de un artículo (el parámetro desconocido) se recogerán observaciones del precio de dicho artículo en diversos establecimientos (la muestra) y la media aritmética de las observaciones puede utilizarse como estimador del precio medio.


Para cada parámetro pueden existir varios estimadores diferentes. En general, escogeremos el estimador que posea mejores propiedades que los restantes, como insesgadez, eficiencia, convergencia y robustez(consistencia).

miércoles, 3 de octubre de 2018
Distribución de Varianzas
| Imprimir | INSTITUTO TECNOLOGICO DE CHIHUAHUA | << Contenido >> |
DISTRIBUCION JI-CUADRADA (X2)
En realidad la distribución ji-cuadrada es la distribución muestral de s2. O sea que si se extraen todas las muestras posibles de una población normal y a cada muestr

Para estimar la varianza poblacional o la desviación estándar, se necesita conocer el estadístico X2. Si se elige una muestra de tamaño n de una población normal con varianza




miércoles, 26 de septiembre de 2018

jueves, 20 de septiembre de 2018
Prueba T student

En las unidades anteriores se manejó el uso de la distribución z, la cual se podía utilizar siempre y cuando los tamaños de las muestras fueran mayores o iguales a 30 ó en muestras más pequeñas si la distribución o las distribuciones de donde proviene la muestra o las muestras son normales.
En esta unidad se podrán utilizar muestras pequeñas siempre y cuando la distribución de donde proviene la muestra tenga un comportamiento normal. Esta es una condición para utilizar las tres distribuciones que se manejarán en esta unidad; t de student, X2 ji-cuadrada y Fisher.
A la teoría de pequeñas muestras también se le llama teoría exacta del muestreo, ya que también la podemos utilizar con muestras aleatorias de tamaño grande.
En esta unidad se verá un nuevo concepto necesario para poder utilizar a las tres distribuciones mencionadas. Este concepto es "grados de libertad".
DISTRIBUCIÓN "t DE STUDENT"
Supóngase que se toma una muestra de una población normal con media  y varianza
y varianza  . Si
. Si  es el promedio de las n observaciones que contiene la muestra aleatoria, entonces la distribución
es el promedio de las n observaciones que contiene la muestra aleatoria, entonces la distribución  es una distribución normal estándar. Supóngase que la varianza de la población
es una distribución normal estándar. Supóngase que la varianza de la población  2 es desconocida. ¿Qué sucede con la distribución de esta estadística si se reemplaza por s? La distribución t proporciona la respuesta a esta pregunta.
2 es desconocida. ¿Qué sucede con la distribución de esta estadística si se reemplaza por s? La distribución t proporciona la respuesta a esta pregunta.
es una distribución normal estándar. Supóngase que la varianza de la población
La media y la varianza de la distribución t son  = 0 y
= 0 y  para
para  >2, respectivamente.
>2, respectivamente.
La siguiente figura presenta la gráfica de varias distribuciones t. La apariencia general de la distribución t es similar a la de la distribución normal estándar: ambas son simétricas y unimodales, y el valor máximo de la ordenada se alcanza en la media = 0. Sin embargo, la distribución t tiene colas más amplias que la normal; esto es, la probabilidad de las colas es mayor que en la distribución normal. A medida que el número de grados de libertad tiende a infinito, la forma límite de la distribución t es la distribución normal estándar.

Propiedades de las distribuciones t
- Cada curva t tiene forma de campana con centro en 0.
- Cada curva t, está más dispersa que la curva normal estándar z.
- A medida que
- A medida que
, la secuencia de curvas t se aproxima a la curva normal estándar, por lo que la curva z recibe a veces el nombre de curva t con gl =
La distribución de la variable aleatoria t está dada por:

Esta se conoce como la distribución t con grados de libertad.
Sean X1, X2, . . . , Xn variables aleatorias independientes que son todas normales con media y desviación estándar . Entonces la variable aleatoria  tiene una distribución t con = n-1 grados de libertad.
tiene una distribución t con = n-1 grados de libertad.
tiene una distribución t con La distribución de probabilidad de t se publicó por primera vez en 1908 en un artículo de W. S. Gosset. En esa época, Gosset era empleado de una cervecería irlandesa que desaprobaba la publicación de investigaciones de sus empleados. Para evadir esta prohibición, publicó su trabajo en secreto bajo el nombre de "Student". En consecuencia, la distribución t normalmente se llama distribución t de Student, o simplemente distribución t. Para derivar la ecuación de esta distribución, Gosset supone que las muestras se seleccionan de una población normal. Aunque esto parecería una suposición muy restrictiva, se puede mostrar que las poblaciones no normales que poseen distribuciones en forma casi de campana aún proporcionan valores de t que se aproximan muy de cerca a la distribución t.
La distribución t difiere de la de Z en que la varianza de t depende del tamaño de la muestra y siempre es mayor a uno. Unicamente cuando el tamaño de la muestra tiende a infinito las dos distribuciones serán las mismas.
Se acostumbra representar con  el valor t por arriba del cual se encuentra un área igual a
el valor t por arriba del cual se encuentra un área igual a  . Como la distribución t es simétrica alrededor de una media de cero, tenemos
. Como la distribución t es simétrica alrededor de una media de cero, tenemos ; es decir, el valor t que deja un área de
; es decir, el valor t que deja un área de  a la derecha y por tanto un área de a la izquierda, es igual al valor t negativo que deja un área de en la cola derecha de la distribución. Esto es, t0.95 = -t0.05, t0.99=-t0.01, etc.
a la derecha y por tanto un área de a la izquierda, es igual al valor t negativo que deja un área de en la cola derecha de la distribución. Esto es, t0.95 = -t0.05, t0.99=-t0.01, etc.
Para encontrar los valores de t se utilizará la tabla de valores críticos de la distribución t del libro Probabilidad y Estadística para Ingenieros de los autores Walpole, Myers y Myers.
Ejemplo:
El valor t con = 14 grados de libertad que deja un área de 0.025 a la izquierda, y por tanto un área de 0.975 a la derecha, es
t0.975=-t0.025 = -2.145

Si se observa la tabla, el área sombreada de la curva es de la cola derecha, es por esto que se tiene que hacer la resta de


Suscribirse a:
Comentarios (Atom)